Serverless Compression of GCS Data With Streaming Golang Google Cloud Function
TL;DR
Compress data and use cold storage tiers to achieve absolute minimum cost for long-term logs archiving at as little as $1.20 per TB per year.
Problem
Imagine you need to capture and store 1TiB of logs monthly and retain them for 10 years - what is the most cost-effective way of doing so (infrastructure cost and long-term maintenance overheads)? Google Cloud produces a lot of audit logging and it is stored in Cloud Logging for free. They give you generous 400 days retention for Admin Activity and System Event logging and 30 days for Data Access. As of recently, they also support Custom retention which allows you to store logs upwards 10 years at a charge of $0.01 per GiB per month (from March 31, 2021). However, pricing stops being favourable when you ingest and retain regular, non-audit logs. Beyond the first 50GiB per project, the charge is hefty $0.50/GiB. We can use Cloud Logging export sinks to route logs directly into GCS, bypassing Cloud Logging’s $0.50 charge. GCS pricing can be found here where standard storage is twice as expensive as Cloud Logging retention, however, Coldline or colder storage classes provide price parity or even considerable savings.
Solution
We want to export logs directly into GCS, bypassing Cloud Logging fee. We also hypothesise that it will be cheaper to incur some cost of compressing the data before long-term storage vs storing uncompressed.
Export all the logs!
First of all, we need to configure Cloud Logging to export all the logs into logging sink of our choice. This is easy when you have a project or two, but what can you do when you have hundreds of projects? [Aggregated sinks] feature to the rescue! It allows us to have an organization-wide logging rules (be careful, this can generate massive amounts of logs).
Here is an example of Aggregated sink configured using Terraform to export all Audit logs into a single bucket.
resource "google_logging_organization_sink" "audit-logging-sink" {
name = "org-audit-logging"
org_id = var.org_id
# apply to the entire org
include_children = true
# Can export to pubsub, cloud storage, or bigquery
destination = "storage.googleapis.com/${google_storage_bucket.bucket-audit-logging.name}"
# Log all AuditLogs
filter = "protoPayload.\"@type\"=type.googleapis.com/google.cloud.audit.AuditLog"
}
Compress all the logs!
With our hypothetical 1TiB logging ingest we can try and save on storage costs by compressing logs first. Logs are usually great candidates for compression due to being plaintext and having a lot of repeating tokens. So imagine that all aggregated logs are arriving in all-logs-export bucket. There is a number of options on how we can achieve compression here:
- Run 24/7 GCE instance which is subscribed to bucket’s PubSub events. Running anything 24/7 sounds expensive and will fail us on our mission of finding the cheapest approach here. It also means a level of a maintenance overhead for the GCE, which is not something that will get reflected in bills, but rather in payroll.
- Run nightly batch processing using GCE and preemptible VM instances. This is likely the absolute best solution in terms of cost per GiB logs compressed. We are only running VMs for short-bursts and VMs are heavily discounted. Short-lived instances are also less of maintenance overhead as each time it is launched up with a latest, patched version of the OS. However, you have to build a trigger to run this nightly, deal with corrupted compression due to the preemptions, scale system if logging suddenly goes x10 or x100.
- Trigger Google Cloud Function each time the object has finished writing into the bucket using Google Cloud Storage Triggers. Compress file and store it in a
all-logs-export-compressedbucket. This is definitely a winner in terms of low maintenance, but how much would it cost? Let’s find out.
Cloud Functions implementation
It is worth to be well aware of Cloud Functions limitations:
- Max execution time is 9min
- Max function memory of 2048MB
- Local data is written to an in-memory volume
- Compute time is proportional to a memory allocated to the function
- Bonus - Cloud Logging export does generate files in excess of 2GiB.
Great, what does it all mean?
It means that Cloud Functions resources are finite and we can not get away with inefficient implementation. Our function must not store files in local storage, because it is backed up by Function’s memory, meaning that we will not have enough memory to store larger log files. Additionally, we must be able to download, compress and upload files larger than 2GiB in less than 9 minutes otherwise our function will stop.
How can we avoid hitting the above limitations?
Streaming. Instead of reading the entire file into memory at once, we are going to incrementally stream download, compress and stream upload the results. This will keep memory usage low, allowing 2048MB function to process files of any size, mainly limited by 9-minute execution limit.
We will write this function in Go to keep its memory usage low, Go also makes the implementation of streaming compression a breeze. We will use cloud.google.com/go/storage and compress/gzip packages in our implementation.
Core logic
func CompressGCSLogs(ctx context.Context, e GCSEvent) error {
client, err := storage.NewClient(ctx)
logging.Logger.Debugf("Compressing file [%s] in [%s] bucket.", e.Name, e.Bucket)
if err != nil {
logging.Logger.Error(err)
return err
}
// 1 Read object from a bucket
rc, err := client.Bucket(e.Bucket).Object(e.Name).NewReader(ctx)
if err != nil {
logging.Logger.Error(err)
return err
}
// 2 Destination bucket and file name (with added .gzip extention)
wc := client.Bucket("all-logs-export-compressed").Object(e.Name + ".gzip").NewWriter(ctx)
//3 Create a gzip writer
gzipWriter := gzip.NewWriter(wc)
if err != nil]
logging.Logger.Error(err)
return err
}
// 4 Write compressed version of the file
if _, err := io.Copy(gzipWriter, rc); err != nil {
logging.Logger.Error(err)
return err
}
if err := wc.Close(); err != nil {
logging.Logger.Error(err)
return err
}
rc.Close()
return nil
}
First try - Deploying Cloud Function
Cloud Function can be deployed using gcloud command. You need to specify source bucket and event type.
gcloud functions deploy CompressGCSLogs \
--runtime go113 \
--trigger-resource all-logs-export \
--trigger-event google.storage.object.finalize \
--project <your-project-name> \
--region <your-region> \
--timeout=540s
Function worked really well and we could see gzip files appearing in all-logs-export-compressed directory. However, Monitoring has shown that some function invocations have failed. Infrequently functions were exceeding 540-second execution limited and getting forcefully stopped.
Second try - Deploying Cloud Function
By default, Cloud Functions are deployed with 256MB of memory, meaning it only has 400Mhz of CPU available to it. GZIPing of large files 1GB+ seems to require more grunt to be able to complete compression within 9-minute slot. The solution is simple, deploy Cloud Function with more memory. While extra memory will go to waste, we will prevent timeouts by completing compression sooner.
I’ve added --memory=1024' parameter to the gcloud command above to effectively x4 available CPU. Now, even the largest files (around 3GB) finish processing in under 3 minutes. I did not use --memory=2048' as it would increase memory waste and be less efficient on smaller sized logs. However, if I’ll notice that processing slows down towards 5 minutes mark, I’ll double memory again.
Achieved result
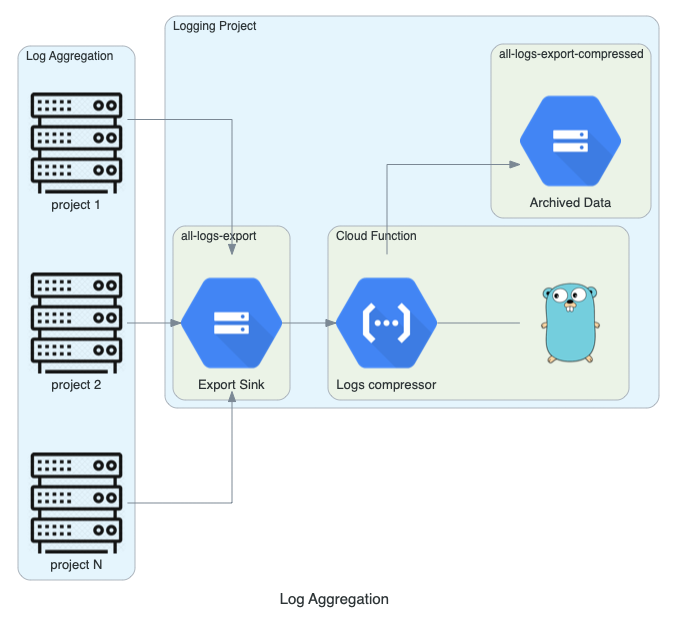
Overall, this solution was quick to implement, easy to debug and should be zero effort to maintain going forward, it should also scale well.
In terms of compression, we observed x12 to x15 size reduction, which we can directly translate into storage cost savings.
gsutil du -hc "gs://abc-audit-logging/cloudaudit.googleapis.com/*/2020/10/02/"
# 61.68 GiB total before compression
gsutil du -hc "gs://abc-audit-logging-compressed/cloudaudit.googleapis.com/*/2020/10/02/"
# 4.66 GiB total after compression
Cloud function runs under 3 minutes.
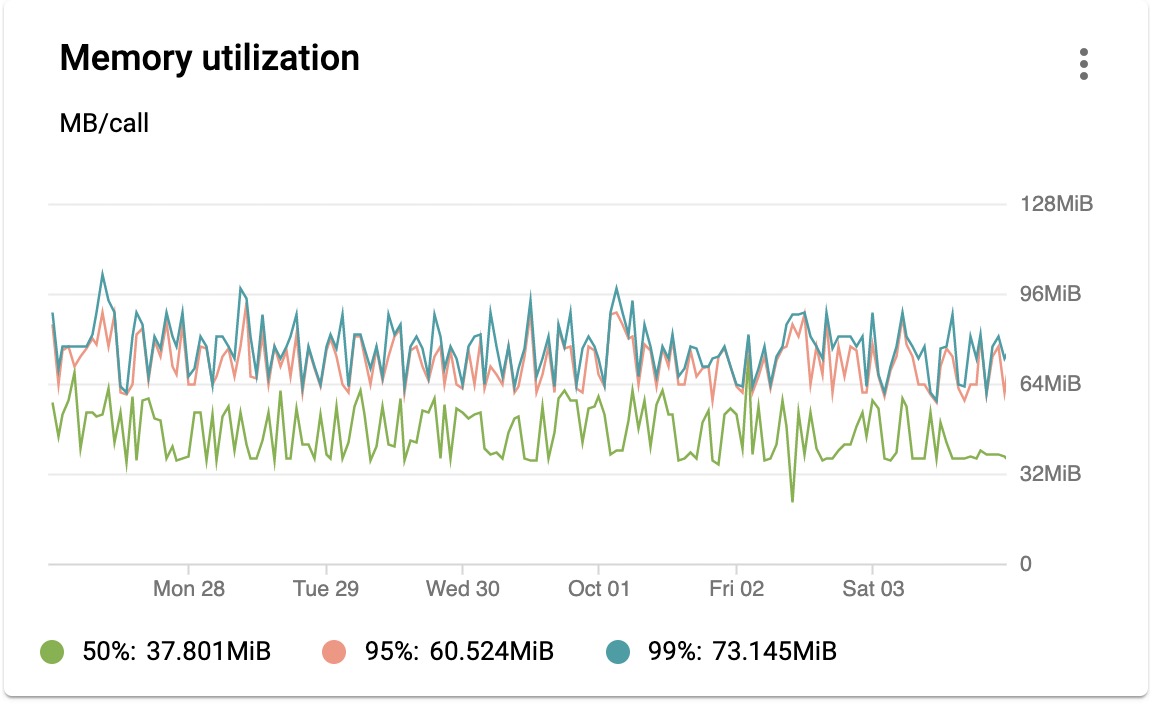
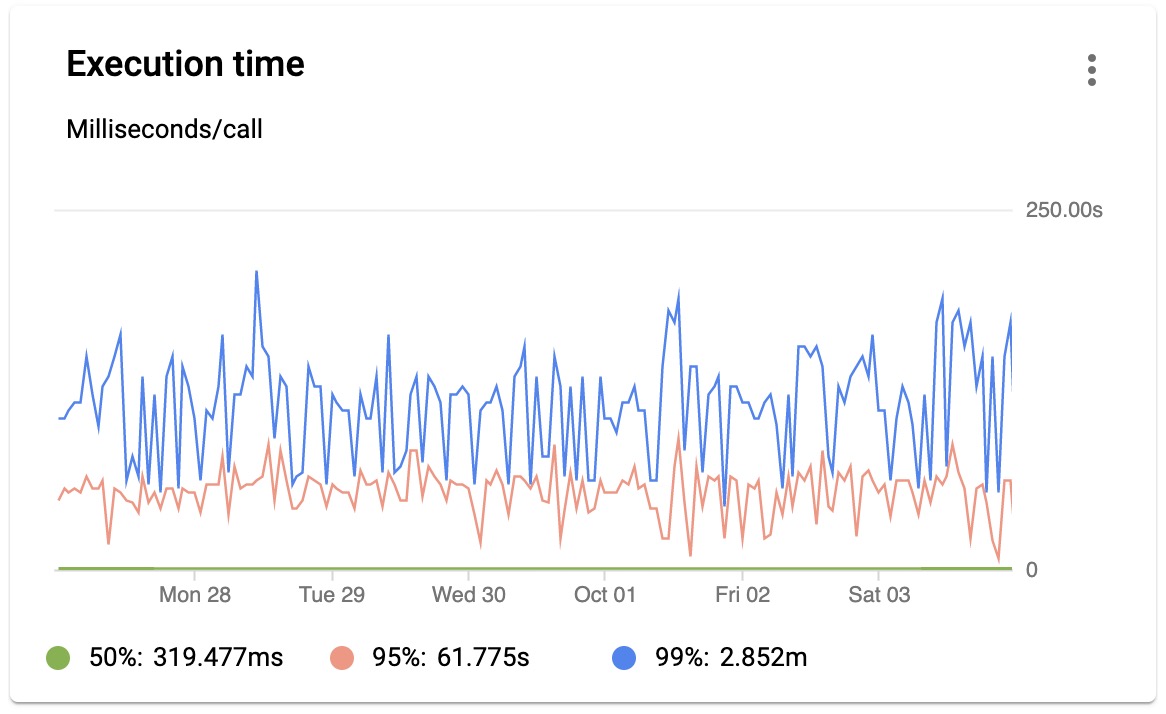 Memory utilization peaks at 100MB.
Memory utilization peaks at 100MB.
How much does this cost?
Cloud Logging
Using Nearline storage class.
| Unit Price | Total for 1000GB for 10 years | |
|---|---|---|
| Processing | $0.50GB | 500 |
| Storage | $0.01GB/month | 1200 |
| Total | 1700 |
GCS Export sink with no compression
Using Nearline storage class.
| Unit Price | Total for 1000GB for 10 years | |
|---|---|---|
| Processing | $0.00GB | 0 |
| Storage | $0.01GB/month | 1200 |
| Total | 1200 |
Cloud Function
Calculating the cost of this method is less straight forward. I’ve taken a sample of processing performed to compress 61.7GB on a day. It included 548 Class A and Class B GCS invocations, 548 Cloud Function invocations, 5624GHz of CPU time and 5017GiB/seconds of Memory time. We can calculate at the per/GB metric to find out a 91GHZ/seconds and 81GiB/seconds values. This means that if you are not using Cloud Functions for anything else in your organization, a free tier (400,000 GB-seconds memory, 200,000 GHz-seconds of compute time) will be enough to compress 2.2TB of logs monthly at no cost, and it will cost only $0.001 per GB thereafter.
So, with compression, 1000GB will become 83GB or less.
Worst case
Using Nearline storage class.
| Unit Price | Total for 1000GB for 10 years | |
|---|---|---|
| Processing | $0.001GB | 1 |
| Storage | $0.01GB/month | 100 |
| Total | 101 |
Best case
Using Archive storage class and free-tier.
| Unit Price | Total for 1000GB for 10 years | |
|---|---|---|
| Processing | $0.00 | 0 |
| Storage | $0.0012GB/month | 11.95 |
| Total | 11.95 |
This is insanely cheap, storing 1TB of logs at $1.20 per year.
Conclusion
It is possible to archive all of the GCP logs for as little as $1.20 per TB per year. Go Cloud Function makes implementation simple and future maintenance minimal. It is also interesting how the cost of a managed solution is x17 times higher, making it worthwhile to implement a custom solution.
Last updated on 12th of October, 2020